The concept of encapsulation revolves around the notion that an object's internal data should not be directly accessible from an object instance. Rather, if the caller wants to alter the state of an object, the user does so indirectly using accessor (i.e., "getter") and mutator (i.e., "setter") methods. In C#, encapsulation is enforced at the syntactic level using the public, private, internal, and protected keywords. To illustrate the need for encapsulation services, assume you have created the following class definition:
// A class with a single public field. class Book { public int numberOfPages; }
The problem with public data is that the data itself has no ability to "understand" whether the current value to which they are assigned is valid with regard to the current business rules of the system. As you know, the upper range of a C# int is quite large (2,147,483,647). Therefore, the compiler allows the following assignment:
// Humm. That is one heck of a mini-novel! static void Main(string[] args) { Book miniNovel = new Book(); miniNovel.numberOfPages = 30000000; }
Although you have not overflowed the boundaries of an int data type, it should be clear that a mininovel with a page count of 30,000,000 pages is a bit unreasonable. As you can see, public fields do not provide a way to trap logical upper (or lower) limits. If your current system has a business rule that states a book must be between 1 and 1,000 pages, you are at a loss to enforce this programmatically. Because of this, public fields typically have no place in a production-level class definition.
Note To be more specific, members of a class that represent an object's state should not be marked as public. As you will see later in this chapter, public constants and public read-only fields are a-okay.
Encapsulation provides a way to preserve the integrity of an object's state data. Rather than defining public fields (which can easily foster data corruption), you should get in the habit of defining private data, which is indirectly manipulated using one of two main techniques:
Whichever technique you choose, the point is that a well-encapsulated class should protect its data and hide the details of how it operates from the prying eyes of the outside world. This is often termed black box programming. The beauty of this approach is that an object is free to change how a given method is implemented under the hood. It does this without breaking any existing code making use of it, provided that the parameters and return values of the method remain constant.
Over the remaining pages in this chapter, you will be building a fairly complete class that models a general employee. To get the ball rolling, create a new Console Application named EmployeeApp and insert a new class file (named Employee.cs) using the Project ? Add class menu item. Update the Employee class with the following fields, methods, and constructors:
class Employee { // Field data. private string empName; private int empID; private float currPay; // Constructors. public Employee() {} public Employee(string name, int id, float pay) { empName = name; empID = id; currPay = pay; } // Methods. public void GiveBonus(float amount) { currPay += amount; } public void DisplayStats() { Console.WriteLine("Name: {0}", empName); Console.WriteLine("ID: {0}", empID); Console.WriteLine("Pay: {0}", currPay); } }
Notice that the fields of the Employee class are currently defined using the private keyword. Given this, the empName, empID, and currPay fields are not directly accessible from an object variable:
static void Main(string[] args) { // Error! Cannot directly access private members // from an object! Employee emp = new Employee(); emp.empName = "Marv"; }
If you want the outside world to interact with a worker's full name, tradition dictates defining an accessor (get method) and a mutator (set method). The role of a 'get' method is to return to the caller the current value of the underlying state data. A 'set' method allows the caller to change the current value of the underlying state data, so long as the defined business rules are met.
To illustrate, let's encapsulate the empName field. To do so, add the following public methods to the Employee class. Notice that the SetName() method performs a test on the incoming data, to ensure the string is 15 characters or less. If it is not, an error prints to the console and returns without making a change to the empName field:
Note If this were a production level class, you would also make to check the character length for an employee's name within your constructor logic. Ignore this detail for the time being, you will clean up this code in just a bit when you examine .NET property syntax.
class Employee { // Field data. private string empName; ... // Accessor (get method) public string GetName() { return empName; } // Mutator (set method) public void SetName(string name) { // Do a check on incoming value // before making assignment. if (name.Length > 15) Console.WriteLine("Error! Name must be less than 16 characters!"); else empName = name; } }
This technique requires two uniquely named methods to operate on a single data point. To test your new methods, update your Main() method as follows:
static void Main(string[] args) { Console.WriteLine("***** Fun with Encapsulation *****\n"); Employee emp = new Employee("Marvin", 456, 30000); emp.GiveBonus(1000); emp.DisplayStats(); // Use the get/set methods to interact with the object's name. emp.SetName("Marv"); Console.WriteLine("Employee is named: {0}", emp.GetName()); Console.ReadLine(); }
Because of the code in your SetName() method, if you attempted to specify more than 15 characters (see below), you would find the hard-coded error message print to the console:
static void Main(string[] args) { Console.WriteLine("***** Fun with Encapsulation *****\n"); ... // Longer than 15 characters! Error will print to console. Employee emp2 = new Employee(); emp2.SetName("Xena the warrior princess"); Console.ReadLine(); }
So far so good. You have encapsulated the private empName field using two methods named GetName() and SetName(). If you were to further encapsulate the data in the Employee class, you would need to add various additional methods (GetID(), SetID(), GetCurrentPay(), SetCurrentPay() for example). Each of the mutator methods could have within it various lines of code to check for additional business rules. While this could certainly be done, the C# language has a useful alternative notation to encapsulate class data.
Although you can encapsulate a piece of field data using traditional get and set methods, .NET languages prefer to enforce data encapsulation state data using properties. First of all, understand that properties are just a simplification for "real" accessor and mutator methods. Therefore, as a class designer, you are still able to perform any internal logic necessary before making the value assignment (e.g., uppercase the value, scrub the value for illegal characters, check the bounds of a numerical value, and so on). Here is the updated Employee class, now enforcing encapsulation of each field using property syntax rather than traditional get and set methods:
class Employee { // Field data. private string empName; private int empID; private float currPay; // Properties! public string Name { get { return empName; } set { if (value.Length > 15) Console.WriteLine("Error! Name must be less than 16 characters!"); else empName = value; } } // We could add additional business rules to the sets of these properties, // however there is no need to do so for this example. public int ID { get { return empID; } set { empID = value; } } public float Pay { get { return currPay; } set { currPay = value; } } ... }
A C# property is composed by defining a get scope (accessor) and set scope (mutator) directly within the property itself. Notice that the property specifies the type of data it is encapsulating by what appears to be a return value. Also take note that, unlike a method, properties do not make use of parentheses (not even empty parentheses) when being defined. Consider the commentary on your current ID property:
// The 'int' represents the type of data this property encapsulates. // The data type must be identical to the related field (empID). public int ID // Note lack of parentheses. { get { return empID; } set { empID = value; } }
Within a 'set' scope of a property, you use a token named value, which is used to represent the incoming value used to assign the property by the caller. This token is not a true C# keyword, but is what is known as a contextual keyword. When the token value is within the set scope of the property, it always represents the value being assigned by the caller, and it will always be the same underlying data type as the property itself. Thus, notice how the Name property can still test the range of the string as so:
public string Name { get { return empName; } set { // Here, value is really a string. if (value.Length > 15) Console.WriteLine("Error! Name must be less than 16 characters!"); else empName = value; } }
Once you have these properties in place, it appears to the caller that it is getting and setting a public point of data; however, the correct get and set block is called behind the scenes to preserve encapsulation:
static void Main(string[] args) { Console.WriteLine("***** Fun with Encapsulation *****\n"); Employee emp = new Employee("Marvin", 456, 30000); emp.GiveBonus(1000); emp.DisplayStats(); // Set and get the Name property. emp.Name = "Marv"; Console.WriteLine("Employee is named: {0}", emp.Name); Console.ReadLine(); }
Properties (as opposed to accessors and mutators) also make your types easier to manipulate, in that properties are able to respond to the intrinsic operators of C#. To illustrate, assume that the Employee class type has an internal private member variable representing the age of the employee. Here is the relevant update (notice the use of constructor chaining):
class Employee { ... // New field and property. private int empAge; public int Age { get { return empAge; } set { empAge = value; } } // Updated constructors public Employee() {} public Employee(string name, int id, float pay) :this(name, 0, id, pay){} public Employee(string name, int age, int id, float pay) { empName = name; empID = id; empAge = age; currPay = pay; } // Updated DisplayStats() method now accounts for age. public void DisplayStats() { Console.WriteLine("Name: {0}", empName); Console.WriteLine("ID: {0}", empID); Console.WriteLine("Age: {0}", empAge); Console.WriteLine("Pay: {0}", currPay); } }
Now assume you have created an Employee object named joe. On his birthday, you wish to increment the age by one. Using traditional accessor and mutator methods, you would need to write code such as the following:
Employee joe = new Employee();
joe.SetAge(joe.GetAge() + 1);
However, if you encapsulate empAge using a property named Age, you are able to simply write
Employee joe = new Employee();
joe.Age++;
Properties, specifically the 'set' portion of a property, are common places to package up the business rules of your class. Currently, the Employee class has a Name property which ensures the name is no more than 15 characters. The remaining properties (ID, Pay and Age) could also be updated with any relevant logic.
While this is well and good, also consider what a class constructor typically does internally. It will take the incoming parameters, check for valid data, and then make assignments to the internal private fields. Currently your master constructor does not test the incoming string data for a valid range, so you could update this member as so:
public Employee(string name, int age, int id, float pay) { // Humm, this seems like a problem... if (name.Length > 15) Console.WriteLine("Error! Name must be less than 16 characters!"); else empName = name; empID = id; empAge = age; currPay = pay; }
I am sure you can see the problem with this approach. The Name property and your master constructor are performing the same error checking! If you were also making checks on the other data points, you would have a good deal of duplicate code. To streamline your code, and isolate all of your error checking to a central location, you will do well if you always use properties within your class whenever you need to get or set the values. Consider the following updated constructor:
public Employee(string name, int age, int id, float pay) { // Better! Use properties when setting class data. // This reduces the amount of duplicate error checks. Name = name; Age = age; ID = id; Pay = pay; }
Beyond updating constructors to use properties when assigning values, it is good practice to use properties throughout a class implementation, to ensure your business rules are always enforced. In many cases, the only time when you directly make reference to the underlying private piece of data is within the property itself. With this in mind, here is your updated Employee cEmployee class:
class Employee { // Field data. private string empName; private int empID; private float currPay; private int empAge; // Constructors. public Employee() { } public Employee(string name, int id, float pay) :this(name, 0, id, pay){} public Employee(string name, int age, int id, float pay) { Name = name; Age = age; ID = id; Pay = pay; } // Methods. public void GiveBonus(float amount) { Pay += amount; } public void DisplayStats() { Console.WriteLine("Name: {0}", Name); Console.WriteLine("ID: {0}", ID); Console.WriteLine("Age: {0}", Age); Console.WriteLine("Pay: {0}", Pay); } // Properties as before... ... }
Many programmers who use traditional accessor and mutator methods, often name these methods using get_ and set_ prefixes (e.g., get_Name() and set_Name()). This naming convention itself is not problematic as far as C# is concerned. However, it is important to understand that under the hood, a property is represented in CIL code using this same naming convention.
For example, if you open up the EmployeeApp.exe assembly using ildasm.exe, you see that each property is mapped to hidden get_XXX()/set_XXX() methods called internally by the CLR (see Figure 5-6).
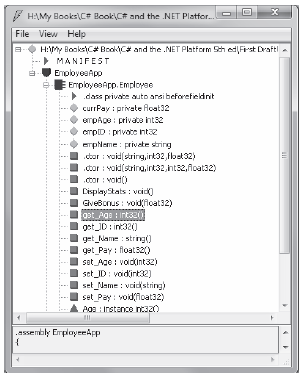
Figure 5-6. A property is represented by get/set methods internally
Assume the Employee type now has a private member variable named empSSN to represent an individual's Social Security number, which is manipulated by a property named SocialSecurityNumber (and also assume you have updated your type's custom constructor and DisplayStats() method to account for this new piece of field data).
// Add support for a new field representing the employee's SSN. class Employee { ... private string empSSN; public string SocialSecurityNumber { get { return empSSN; } set { empSSN = value; } } // Constructors public Employee() { } public Employee(string name, int id, float pay) :this(name, 0, id, pay, ""){} public Employee(string name, int age, int id, float pay, string ssn) { Name = name; Age = age; ID = id; Pay = pay; SocialSecurityNumber = ssn; } public void DisplayStats() { Console.WriteLine("Name: {0}", Name); Console.WriteLine("ID: {0}", ID); Console.WriteLine("Age: {0}", Age); Console.WriteLine("Pay: {0}", Pay); Console.WriteLine("SSN: {0}", SocialSecurityNumber); } ... }
If you were to also define two methods named get_SocialSecurityNumber() and set_SocialSecurityNumber() in the same class, you would be issued compile-time errors:
// Remember, a property really maps to a get_/set_ pair! class Employee { ... public string get_SocialSecurityNumber() { return empSSN; } public void set_SocialSecurityNumber(string ssn) { empSSN = ssn; } }
Note The .NET base class libraries always favor type properties over traditional accessor and mutator methods when encapsulating field data. Therefore, if you wish to build custom classes that integrate well with the .NET platform, avoid defining traditional get and set methods.
Unless you say otherwise, the visibility of get and set logic is solely controlled by the access modifier of the property declaration:
// The get and set logic is both public, // given the declaration of the property. public string SocialSecurityNumber { get { return empSSN; } set { empSSN = value; } }
In some cases, it would be useful to specify unique accessibility levels for get and set logic. To do so, simply prefix an accessibility keyword to the appropriate get or set keyword (the unqualified scope takes the visibility of the property's declaration):
// Object users can only get the value, however // the Employee class and derived types can set the value. public string SocialSecurityNumber { get { return empSSN; } protected set { empSSN = value; } }
In this case, the set logic of SocialSecurityNumber can only be called by the current class and derived classes and therefore cannot be called from an object instance. Again, the protected keyword will be formally detailed in the next chapter when we examine inheritance and polymorphism.
When encapsulating data, you may wish to configure a read-only property. To do so, simply omit the set block. Likewise, if you wish to have a write-only property, omit the get block. While there is no need to do so for the current example, here is how the SocialSecurityNumber property could be retrofitted as readonly:
public string SocialSecurityNumber { get { return empSSN; } }
Given this adjustment, the only manner in which an employee's US Social Security number can be set is through a constructor argument. Therefore, it would now be a compiler error to attempt to set an employee's SSN value within your master constructor:
public Employee(string name, int age, int id, float pay, string ssn) { Name = name; Age = age; ID = id; Pay = pay; // OOPS! This is no longer possible if the property is read // only. SocialSecurityNumber = ssn; }
If you did make this property read only, your only choice would be to use the underlying ssn member variable within your constructor logic.
C# also supports static properties. Recall from earlier in this chapter that static members are accessed at the class level, not from an instance (object) of that class. For example, assume that the Employee type defines a static point of data to represent the name of the organization employing these workers. You may encapsulate a static property as follows:
// Static properties must operate on static data! class Employee { ... private static string companyName; public static string Company { get { return companyName; } set { companyName = value; } } ... }
Static properties are manipulated in the same manner as static methods, as shown here:
// Interact with the static property. static void Main(string[] args) { Console.WriteLine("***** Fun with Encapsulation *****\n"); // Set company. Employee.Company = "My Company"; Console.WriteLine("These folks work at {0}.", Employee.Company); Employee emp = new Employee("Marvin", 24, 456, 30000, "111-11-1111"); emp.GiveBonus(1000); emp.DisplayStats(); Console.ReadLine(); }
Finally, recall that classes can support static constructors. Thus, if you wanted to ensure that the name of the static companyName field was always assigned to "My Company," you would write the following:
// Static constructors are used to initialize static data. public class Employee { private Static companyName As string ... static Employee() { companyName = "My Company"; } }
Using this approach, there is no need to explicitly call the Company property to set the initial value:
// Automatically set to "My Company" via static constructor. static void Main(string[] args) { Console.WriteLine("These folks work at {0}", Employee.Company); }
To wrap up the story thus far, recall that C# prefers properties to encapsulate data. These syntactic entities are used for the same purpose as traditional accessor (get)/mutator (set) methods. The benefit of properties is that the users of your objects are able to manipulate the internal data point using a single named item.
Source Code The EmployeeApp project can be found under the Chapter 5 subdirectory.